


Như chúng ta đã biết qua các bài trước, ứng dụng mạng là một hệ thống phần mềm chạy trên các thiết bị đầu cuối khác nhau và trao đổi thông tin qua mạng máy tính.
“Hệ thống” ở đây mang ý nghĩa rằng ứng dụng mạng bao gồm nhiều thành phần phối hợp hoạt động với nhau trong một thể thống nhất. Sự phối hợp có được nhờ môi trường mạng (cho phép trao đổi thông tin) và giao thức truyền thông (các quy tắc chi phối quá trình trao đổi thông tin).
Ngoài các yếu tố trên, sự phối hợp trong hệ thống phần mềm mạng còn thể hiện ở sự thỏa thuận về mặt nhiệm vụ giữa các thành phần. Sự thỏa thuận đó thể hiện qua mô hình (hay kiến trúc) ứng dụng mạng.
Trong bài học này chúng ta tiếp tục đi sâu vào các vấn đề của ứng dụng mạng, bao gồm các mô hình của ứng dụng mạng (mô hình client – server, mô hình p2p) và truyền thông liên tiến trình trong ứng dụng mạng.
Mô hình ứng dụng mạng
Khi bắt tay vào xây dựng một ứng dụng mạng, một trong những vấn đề đầu tiên đặt ra chính là lựa chọn mô hình (đôi khi cũng được gọi là kiến trúc) cho ứng dụng mạng. Mặc dù phần mềm mạng rất đa dạng nhưng có thể phân chia chúng vào 2 mô hình cơ bản theo cách thức phân chia vai trò nhiệm vụ của các thành phần: mô hình chủ-khách (client-server) và mô hình ngang hàng (peer-to-peer, P2P).
Mô hình chủ – khách (client – server)
Trong mô hình chủ-khách ứng dụng được chia làm hai thành phần: một thành phần chuyên phục vụ các yêu cầu gửi đến từ các thành phần khác, gọi là thành phần server; một hoặc nhiều thành phần đưa ra yêu cầu sử dụng dịch vụ, gọi là thành phần client.
Server và client chạy trên các thiết bị đầu cuối khác nhau khác nhau. Thiết bị đầu cuối nơi chạy chương trình server cũng thường được gọi tắt là máy chủ (trên máy chủ vật lý đó cũng thường cài đặt nhiều chương trình server khác nhau). Thiết bị đầu cuối nơi chạy chương trình client thường được gọi tắt là máy khách hay máy trạm.
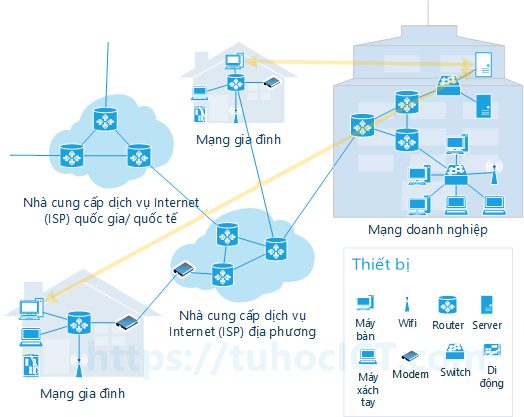
Một số ứng dụng phổ biến sử dụng mô hình chủ-khách bao gồm Web, FTP, Telnet, Email.
Ví dụ, hệ thống web bao gồm một chương trình luôn hoạt động (chương trình máy chủ web) trên một máy tính riêng có IP cố định để chờ phục vụ các truy vấn đến từ các chương trình trình duyệt (browser). Khi chương trình máy chủ nhận được một truy vấn từ trình duyệt, nó sẽ xử lý và trả lại dữ liệu mà trình duyệt yêu cầu. Các trình duyệt chỉ trao đổi thông tin với chương trình máy chủ mà không tương tác trực tiếp với nhau. Quá trình trao đổi thông tin truy vấn / phản hồi giữa chương trình máy chủ và trình duyệt được hỗ trợ bởi giao thức Http.
Chế độ hoạt động
Trong mô hình này, server luôn hoạt động (chế độ luôn mở) để chờ phục vụ client. Chương trình server phải hoạt động trên máy có địa chỉ IP cố định.
Client có thể hoạt động ở chế độ luôn mở (always-on) hoặc mở không thường xuyên (sometimes-on). Các client không giao tiếp trực tiếp với nhau mà chỉ giao tiếp với server. Chương trình client phải biết được địa chỉ IP của máy chủ.
Do chương trình server luôn hoạt động và chạy trên máy tính có IP cố định và được công bố, chương trình khách có thể liên lạc với máy chủ bất kỳ khi nào cần sử dụng dịch vụ do chương trình máy chủ cung cấp.
Giao tiếp client – server
Việc giao tiếp giữa client và server được thực hiện dưới hình thức trao đổi các thông điệp (message):
- Client gửi thông điệp yêu cầu (request message) cho server để mô tả công việc cần thực hiện.
- Khi nhận được thông điệp này, server sẽ phân tích và xác định công việc phải thực hiện.
- Nếu quá trình xử lý sinh ra kết quả cần trả cho client thì server sẽ gửi cho client thông điệp trả lời (reply message).
- Định dạng và ý nghĩa của các thông điệp trao đổi giữa client và server được quy định bởi giao thức dùng trong ứng dụng.
Thin client, Fat client
Trong mô hình chủ khách, tùy thuộc vào việc phân phố nhiệm vụ giữa client và server, người ta phân chia làm hai loại client: fat client, và thin client.
Trong mô hình sử dụng fat client, server chủ yếu chịu trách nhiệm truy vấn và lưu trữ thông tin. Mô hình này tạo ra ít lưu thông trên mạng do dữ liệu được lưu trữ tạm thời và tính toán ở client nhưng yêu cầu cấu hình máy khách cao hơn.
Trong mô hình dùng thin client, client chỉ cần hiển thị và kiểm tra tính hợp lệ của dữ liệu người dùng nhập vào. Mô hình này cho phép tạo ra các client nhẹ và đơn giản nhưng làm tăng lưu thông trên mạng do dữ liệu phải chuyển qua lại liên tục giữa client và server.
Server và Data center
Thông thường trong ứng dụng client/server, một máy chủ (vật lý) đơn lẻ thường không đủ khả năng phục vụ tất cả truy vấn từ client. Ví dụ, một website mạng xã hội lớn sẽ rất nhanh bị quá tải nếu chỉ có một server phục vụ.
Vì lý do này người ta tạo ra các trung tâm dữ liệu (data center) chứa số lượng lớn máy (vật lý) để cùng tạo một server (ảo) đủ mạnh. Ví dụ, theo thống kê (wikipedia) Google có từ 30 đến 50 data center phân bố khắp thế giới vởi khoảng hơn hai triệu máy chủ để cùng phục vụ yêu cầu tìm kiếm, dịch vụ Gmail và YouTube. Mỗi data center chứa hàng trăm ngàn máy chủ vật lý.
Mô hình ngang hàng
Trong kiến trúc ngang hàng (còn gọi là kiến trúc peer-to-peer hay viết tắt là P2P), tất cả các thành phần của hệ thống đều thực hiện các nhiệm vụ giống nhau, không có người phục vụ (server) chuyên biệt.
Như vậy, trong ứng dụng P2P không có sự phụ thuộc (hoặc phụ thuộc rất ít) vào server. Mỗi ứng dụng chạy trên một máy gọi là peer. Ứng dụng trên mỗi đôi máy (các peer) trực tiếp tiến hành truyền thông với nhau mà không phải thông qua một server trung gian nào. Vì lý do này mô hình được gọi là peer-to-peer. Các peer này không do các nhà cung cấp dịch vụ quản lý mà thực chất là các máy tính cá nhân do người dùng quản lý.
Hiện nay các ứng dụng đòi hỏi lưu lượng dữ liệu lớn thường hoạt động theo mô hình P2P: ứng dụng phân phối file (BitTorrent, µTorrent), ứng dụng chia sẻ file (eMule, LimeWire), điện thoại Internet (Skype), truyền hình IP (PPLive).
Ưu điểm của P2P
Một trong những ưu điểm của kiến trúc P2P là khả năng mở rộng.
Ví dụ, trong ứng dụng chia sẻ file P2P, mặc dù mỗi peer trong khi yêu cầu file tự tạo ra một khối lượng công việc cho mình, mỗi peer đồng thời bổ sung khả năng phục vụ của mình cho hệ thống bằng cách phân phối lại file cho các peer khác.
Kiến trúc P2P cũng có ưu thế về giá thành vì nó không đòi hỏi hạ tầng về máy chủ và băng thông.
Nhược điểm của P2P
Ứng dụng P2P cũng gặp những khó khăn nhất định.
Thứ nhất, các nhà cung cấp dịch vụ Internet (ISP) cho hộ gia đình thường để tốc độ tải xuống lớn hơn tốc độ tải lên. Trong khi đó, dịch vụ phát video (streaming) hoặc phân phối file P2P đều đòi hỏi tốc độ tải lên cao. Từ đó, ISP địa phương phải chịu áp lực lớn về băng thông. Người ta gọi đây là tình trạng “không thân thiện” giữa ứng dụng P2P và ISP.
Thứ hai, do bản chất mở và phân tán, ứng dụng P2P có hạn chế về tính an toàn và bảo mật. Ngoài ra, ứng dụng P2P cũng dễ dàng liên quan tới các vấn đề vi phạm bản quyền vì dữ liệu chia sẻ không bị kiểm soát.
Vấn đề thứ ba là sự thành công của ứng dụng P2P phụ thuộc vào khả năng “thuyết phục” người dùng tham gia vào mạng lưới ứng dụng P2P. Khi tham gia, người dùng sẽ phải “tự nguyện” cung cấp tài nguyên của máy tính cá nhân cho ứng dụng như băng thông, lưu trữ, CPU. Ví dụ, khi tham gia vào hệ thống chia sẻ file P2P, mỗi phần mềm trên máy tính cá nhân đều phải chiếm dụng thêm băng thông, ổ cứng, thời gian xử lý của CPU và cung cấp tài nguyên này cho hệ thống cùng sử dụng.
Ngoài hai mô hình trên, hiện nay một số ứng dụng sử dụng kiến trúc lai, kết hợp cả mô hình chủ-khách và mô hình P2P. Ví dụ, trong nhiều ứng dụng nhắn tin tức thời, server chỉ dùng để theo dõi địa chỉ IP của người dùng, còn tin nhắn giữa người dùng được truyền trực tiếp giữa các máy khách mà không đi qua máy chủ.
Mô hình trao đổi thông điệp trong ứng dụng mạng
Trong một ứng dụng mạng, bên cạnh sự phân chia theo chức năng nhiệm vụ, một vấn đề quan trọng khác cũng quyết định kiến trúc của hệ thống, đó là mô hình trao đổi thông điệp.
Khái niệm mô hình trao đổi thông điệp
Mô hình trao đổi thông điệp (messaging pattern), cũng được gọi là mô hình giao tiếp, là một mẫu kiến trúc mô tả cách kết nối và tương tác giữa các thành phần khác nhau của một hệ thống phần mềm phân tán, và xác định cách thức thông điệp được trao đổi trong một hệ thống phần mềm phân tán.
Mô hình trao đổi thông điệp giúp tách biệt các thành phần của hệ thống, cho phép chúng hoạt động độc lập với nhau. Điều này giúp giảm độ phức tạp của hệ thống, dễ dàng mở rộng và bảo trì. Nó cũng cho phép giao tiếp giữa các ứng dụng chạy trên các nền tảng khác nhau (máy chủ, máy tính cá nhân, điện thoại di động và thiết bị IoT) và được phát triển bởi các ngôn ngữ lập trình khác nhau.
Người ta cũng xây dựng nhiều giao thức trao đổi thông điệp. Có thể hình dung các giao thức trao đổi thông điệp là những giao thức ở tầng ứng dụng nhưng “đa năng”, thay vì chỉ phục vụ mục đích riêng của loại ứng dụng đó. Các giao thức trao đổi thông điệp phổ biến trong ứng dụng mạng bao gồm ZeroMQ, MQTT, AMQP.
Các giao thức trao đổi thông điệp đều hỗ trợ một hoặc một số mô hình trao đổi thông điệp. Có rất nhiều mô hình trao đổi thông điệp khác nhau. Ở đây chúng ta chỉ xem xét một số mô hình phổ biến và được ứng dụng nhiều.
Mô hình truy vấn phản hồi
Mô hình truy vấn phản hồi cũng được gọi là mô hình request / response hoặc mô hình request / reply.
Trong mô hình truy vấn / phản hồi, có hai thành phần chính:
- Thành phần gửi yêu cầu (requester): Thành phần này gửi yêu cầu và chờ đợi phản hồi tương ứng.
- Thành phần nhận yêu cầu và phản hồi (responder): Thành phần này chuyên nhận yêu cầu và phản hồi tương ứng.
Trong mô hình này, các thành phần requester không trao đổi thông tin trực tiếp với nhau. Requester chỉ trao đổi thông tin với responder. Do đó, nó tạo ra kiểu trao đổi thông tin 1 – 1 (unicast) truyền hai chiều không đồng thời (half-duplex).
Đây là mô hình trao đổi thông điệp rất phổ biến trong kiến trúc client / server. Trong kiến trúc này, client thường đóng vai trò requester, và server đóng vai trò responder.
Mô hình truy vấn phản hồi được sử dụng phổ biến trong các giao thức “cổ điển” như HTTP, FTP, các giao thức cho thư điện tử (SMTP, POP).
Mô hình publish / subscribe
Mô hình publish / subscribe cũng thường được gọi tắt là mô hình pub / sub, hoặc dịch sang tiếng Việt là mô hình xuất bản / đăng ký.
Trong mô hình pub/sub, các thành phần trong hệ thống được chia thành hai nhóm chính:
- Publisher (người xuất bản): Đây là thành phần tạo ra các thông điệp. Mỗi thông điệp sẽ có một chủ đề xác định. Các thông điệp được gửi đến một trung tâm trung gian (message broker). Bản thân publisher không biết ai sẽ nhận được thông điệp của mình. Trung tâm này sẽ chuyển tiếp thông điệp khi có subscriber (người đăng ký) đăng ký nhận thông điệp theo chủ đề đó.
- Subscriber (người đăng ký): Đây là thành phần đăng ký để nhận các thông điệp từ trung tâm trung gian (message broker). Subscriber chỉ nhận các thông điệp theo chủ đề mà nó đã đăng ký nhận.
Trong mô hình pub/sub, các thông điệp được phân phối đến các Subscriber đồng thời và không đồng bộ. Điều này đảm bảo rằng mỗi Subscriber chỉ nhận các thông điệp mà nó quan tâm và không cần phải xử lý các thông điệp không cần thiết. Nó cũng cho phép các thành phần trong hệ thống hoạt động độc lập với nhau và không phụ thuộc vào sự hiện diện của nhau.
Mô hình pub / sub tạo ra kiểu trao đổi thông tin 1 – nhiều (multicast / broadcast) giữa 1 publisher và nhiều subscriber.
Mô hình pub / sub có hai kiểu triển khai. Kiểu thứ nhất sử dụng một một broker riêng biệt. Kiểu thứ hai sử dụng luôn publisher làm broker.
Mô hình pub / sub được sử dụng nhiều trong các ứng dụng IoT. Mô hình này khi áp dụng trong phần mềm thường sẽ sử dụng mô hình bất đồng bộ và hướng sự kiện. Mô hình này cũng cho phép mỗi phần mềm trong hệ thống có thể đồng thời gửi (publish) và nhận (subscribe) dữ liệu. Do đó mô hình này rất phù hợp cho việc điều khiển các thiết bị, cũng như thu thập dữ liệu từ các thiết bị phân tán.
Mô hình pipeline
Mô hình pipeline còn được gọi là mô hình push / pull. Trong mô hình này, có hai loại ứng dụng: pusher (người đẩy) và puller (người kéo). Pusher là người gửi các thông điệp qua đường ống và puller là người nhận các thông điệp đó. Mỗi pusher có thể gửi các thông điệp đến nhiều puller, và mỗi puller cũng có thể nhận thông điệp từ nhiều pusher.
Các thông điệp được truyền qua đường ống một cách tuần tự, theo đúng thứ tự gửi. Tuy nhiên, thường các giao thức hỗ trợ mô hình này không đảm bảo rằng các thông điệp sẽ đến đích theo đúng thứ tự gửi. Do đó các ứng dụng phải tự quản lý thứ tự của các thông điệp.
Mô hình giao tiếp pipeline thường được sử dụng trong các hệ thống xử lý dữ liệu lớn, khi các ứng dụng cần xử lý dữ liệu theo một quy trình liên tục, từng bước một. Khi một bước xử lý hoàn thành, kết quả của nó được truyền đến bước tiếp theo để tiếp tục xử lý.
Tiến trình
Khi một chương trình được tải vào bộ nhớ và bắt đầu thực hiện cách lệnh của mình, nó được gọi là một tiến trình (process). Như vậy, một ứng dụng mạng (khi hoạt động) sẽ bao gồm ít nhất hai tiến trình (process) hoạt động trên hai thiết bị đầu cuối khác nhau. Các tiến trình này trao đổi các thông điệp qua mạng. Việc trao đổi thông tin này được gọi là truyền thông liên tiến trình.
Ví dụ, Trong hệ thống web, tiến trình chạy trên máy khách (tiến trình của browser) trao đổi với tiến trình của máy chủ web; trong hệ thống chia sẻ file P2P, file được truyền từ một tiến trình trên một peer (một máy tính) tới một tiến trình trên một peer khác.
Tiến trình chủ, tiến trình khách
Với mỗi cặp tiến trình như vậy, chúng ta thường gọi một tiến trình là tiến trình chủ (server process, server) và tiến trình còn lại là tiến trình khách (client process, client).
Ví dụ, trong ứng dụng web, trình duyệt là tiến trình khách còn web server là tiến trình chủ. Trong ứng dụng chia sẻ P2P, peer tải file về được coi là tiến trình khách, còn peer tải file lên được gọi là tiến trình chủ.
Trong phạm vi của phiên truyền thông giữa một cặp tiến trình, tiến trình nào khởi tạo quá trình truyền thông được gọi là tiến trình khách, tiến trình nào chờ để được liên lạc thì gọi là tiến trình chủ.
Chúng ta có thể thấy như trong ứng dụng chia sẻ P2P, một tiến trình có thể là chủ, cũng có thể là khách (chú ý, trong mô hình P2P các tiến trình tham gia vào truyền thông chỉ phân chia chủ khách trong phạm vi của phiên truyền thông).
Quá trình giao tiếp giữa tiến trình chủ và khách có thể diễn ra theo chế độ: chế độ nghẽn (blocking), chế độ không nghẽn (non-blocking).
Trong chế độ nghẽn, khi tiến trình khách hoặc chủ phát ra lệnh gửi dữ liệu, tiến trình sẽ bị tạm dừng cho đến khi tiến trình nhận phát ra lệnh nhận dữ liệu. Tương tự, khi tiến trình phát ra lệnh nhận dữ liệu mà chưa có dữ liệu gửi đến, tiến trình sẽ bị tạm dừng cho đến khi có dữ liệu tới.
Ở chế độ không nghẽn, khi tiến trình chủ hoặc khách phát ra lệnh gửi dữ liệu, sự thực thi của nó vẫn tiếp tục, không quan tâm tới việc có tiến trình nào phát ra lệnh nhận dữ liệu đó hay không.
Đánh địa chỉ tiến trình
Các loại địa chỉ
Các tiến trình nếu tham gia vào quá trình truyền thông mạng bắt buộc phải lựa chọn một trong hai giao thức của tầng giao vận làm công cụ truyền thông tin liên tiến trình. Các giao thức tầng giao vận, đến lượt mình, phải “trông cậy” vào giao thức IP để có thể truyền các gói tin của mình đến máy đầu cuối. Tại máy nhận, các gói tin IP được ghép nối và chuyển lên tầng giao vận, sau đó chuyển đến cho tiến trình đang chờ nhận thông tin.
Để quá trình truyền thông phức tạp này có thể thực hiện, các thành phần tham gia cần được đánh địa chỉ để có thể xác định được đích đến của các gói tin. Việc đánh địa chỉ này bao gồm hai phần: địa chỉ máy và địa chỉ tiến trình.
Địa chỉ của mỗi máy tham gia vào mạng truyền thông sử dụng bộ giao thức TCP/IP được gọi là địa chỉ IP. Địa chỉ này xác định duy nhất một máy trên liên mạng và là điều kiện để giao thức IP hoạt động. Mỗi giao diện mạng khi tham gia vào quá trình truyền thông đều được gán một địa chỉ IP.
Trên một máy tính thông thường có nhiều tiến trình cùng hoạt động. Mỗi khi các gói tin đến đích cần một cơ chế để có thể phân biệt gói tin đó cần gửi đến cho tiến trình nào. Do đó, mỗi tiến trình khi tham gia vào quá trình truyền thông được gán một địa chỉ riêng, gọi là số cổng (port number).
Số cổng
Cổng (Port) là một số bất kỳ nằm trong khoảng từ 0 đến 65535. Các tiến trình có thể chọn ngẫu nhiên bất kỳ giá trị số cổng nào, miễn là giá trị đó chưa được sử dụng cho tiến trình khác.
Các tiến trình tham gia vào quá trình truyền thông phải thỏa thuận được với nhau về giá trị cổng. Các giá trị cổng nguồn (tiến trình gửi) và cổng đích (tiến trình nhận) đều được gửi đi kèm gói tin TCP (hoặc UDP) để các máy có thể xác định được cần chuyển gói tin đến cho tiến trình nào.
Tổ hợp của địa chỉ IP và số cổng có thể đại diện cho một tiến trình trong mạng truyền thông và được gọi là địa chỉ của tiến trình. Cấu trúc địa chỉ này như sau: địa_chỉ_IP:số_cổng.
Ví dụ, 192.168.1.10:80 là địa chỉ đại diện cho một tiến trình chạy trên máy có địa chỉ IP 192.18.1.10 và chiếm cổng 80. Thực tế, có thể xác định đây là địa chỉ của một chương trình máy chủ web sử dụng giao thức HTTP.
Cổng dành riêng
Mặc dù giá trị số cổng có thể gán ngẫu nhiên cho các tiến trình, một số ứng dụng mạng luôn chiếm một cổng cố định. Ví dụ, chương trình máy chủ web khi chạy luôn chiếm cổng 80, chương trình máy chủ FTP chiếm cổng 20, 21. Đây là những ứng dụng mạng phổ biến đi kèm với giao thức tầng ứng dụng của riêng chúng.
Giá trị cổng mà các chương trình này chiếm dụng được quy định trong các bảng đặc tả của giao thức. Các số cổng từ 0 đến 1023 thường được dùng cho các dịch vụ hệ thống hoặc các chương trình ứng dụng mạng phổ biến và thường được gọi là “cổng nổi tiếng” hoặc “cổng hệ thống”.
Dưới đây là danh sách một số cổng được “chiếm dụng” sẵn bởi các ứng dụng / giao thức mạng phổ biến:
| Số cổng | Ứng dụng / Dịch vụ |
| 20 | FTP – Kênh dữ liệu |
| 21 | FTP – Kênh điều khiển |
| 22 | SSH Remote Login Protocol |
| 23 | Telnet |
| 25 | Simple Mail Transfer Protocol (SMTP) |
| 53 | Domain Name System (DNS) |
| 80 | HTTP |
| 110 | POP3 |
| 161 | SNMP |
| 443 | HTTPS |
| 546 | DHCP Client |
| 547 | DHCP Server |

 offline và các khái niệm cơ bản")


{kind=link}
“Trong mô hình fat client, server chủ yếu chịu trách nhiệm truy vấn và lưu trữ thông tin. Mô hình này tạo ra ít lưu thông trên mạng do dữ liệu được lưu trữ tạm thời và tính toán ở client nhưng yêu cầu cấu hình máy khách cao hơn”
Có sự nhầm lẫn gì ở câu này không Chị nhỉ?